Regression
Purpose
This chapter demonstrates how to solve a simple linear regression problem, including fitting the model, computing residuals, computing the coefficient of determination (![]() ), and related quantities, conducting a model utility test, and computing predictions and prediction intervals for the model.
), and related quantities, conducting a model utility test, and computing predictions and prediction intervals for the model.
The notebook builds on, and is intended to support the study of linear regression in Chapter 12 of Jay L. Devore's Probability and Statistics for Engineering and the Sciences.
Mathematica Solution
The starting point is a data set, either read in from disk, or typed in manually. This data set is the weight of terrestrial animal's brains against total body weight (data provided by Cadet Kaiser, from <>)
Note: this is relatively advanced Mathematica manipulation, using the "DataManipulation" subpackage (part of the Statistics package). For more discussion of how to use the data manipulation package, see Abell et al., particularly Chapter 2, where the basic approach is discussed and several examples given. The specific approach used here is slightly different
Obviously, the specific file name will vary depending on where the data file is located. This particular example is copied from the data disk supplied with Devore into my lesson planning directory.
In[232]:=
![]()
![]()
Out[232]=
![]()
If we were reading data from file, the following is how
In[74]:=
filename="E:\\Kaiser_HW#2_MA206_Z3.txt"
axesnames=ReadList[filename,Word,2,WordSeparators→{",","\t"}];
textdata=ReadList[filename,Word,WordSeparators→{"\t",","},RecordLists→True]
dataTable=Delete[ToExpression[textdata],1]
x=Flatten[ColumnTake[dataTable,1]]
y=Flatten[ColumnTake[dataTable,{2}]]
In[234]:=
![]()

![]()
![]()
![]()
Out[234]=
![]()
Out[236]=

Out[237]=

Out[238]=
![]()
As a first step, plot the data to see if they have a reasonably linear relationship. If not, it is inappropriate to be using the simple linear regression model we are discussing; other—more advanced—techniques will be needed than this worksheet provides.
In[239]:=
![dataPlot = ListPlot[dataTable, Prolog→ {PointSize[0.01]}, AxesLabel→axesnames, DisplayFunction→Identity] ; Show[dataPlot, DisplayFunction→$DisplayFunction] ;](../HTMLFiles/index_666.gif)
![[Graphics:../HTMLFiles/index_667.gif]](../HTMLFiles/index_667.gif)
Required
Fit a linear model using the Principle of Least Squares.
Compute statistics related to model quality.
Conduct a model utility test.
Predict values of the response value given values of the predictor variable. Create prediction intervals on the predicted value.
Model
The model appropriate to this problem is
![]()
where ![]() and
and ![]() are (unknown) coefficients of the best fit line, and ε is assumed to be N(0,
are (unknown) coefficients of the best fit line, and ε is assumed to be N(0,![]() ).
).
For clarity, this notebook uses the following notation (similar, but not identical, to Devore's notation).
![]() : the y-intercept of the true equation. It is estimated by
: the y-intercept of the true equation. It is estimated by ![]() , and the specific value of the point estimate in this problem is defined to be
, and the specific value of the point estimate in this problem is defined to be ![]() .
.
![]() : the slope of the true equation. It is estimated by
: the slope of the true equation. It is estimated by ![]() , and the specific value of the point estimate in this problem is defined to be
, and the specific value of the point estimate in this problem is defined to be ![]() .
.
![]() : the standard deviation of ε, the error term in the model. It is estimated by
: the standard deviation of ε, the error term in the model. It is estimated by ![]() ; the point estimate of
; the point estimate of ![]() is s. Note that Devore uses σ as his symbol for this quantity; using
is s. Note that Devore uses σ as his symbol for this quantity; using ![]() is a reminder of which standard deviation we are dealing with.
is a reminder of which standard deviation we are dealing with.
In many equations, Devore uses the general symbol for the estimator he is interested in; ![]() , for example. Unless there is a specific reason for following Devore's (more abstractly correct) notation, the computational formulæ in this notebook use the specific value of the point estimate
, for example. Unless there is a specific reason for following Devore's (more abstractly correct) notation, the computational formulæ in this notebook use the specific value of the point estimate
Fitting the Model
Following Devore, we compute intermediate quantities n, Sxy and Sxx (which will be used later as well)
In[240]:=
![Sxy = Sum[x[[i]] * y[[i]], {i, 1, n}] - (Sum[x[[i]], {i, 1, n}] * Sum[y[[i]], {i, 1, n}])/n ;](../HTMLFiles/index_683.gif)
![Sxx = Sum[x[[i]]^2, {i, 1, n}] - Sum[x[[i]], {i, 1, n}]^2/n ;](../HTMLFiles/index_684.gif)
![TableForm[{{"n", "=", n}, {"Sxy", "=", N[Sxy]}, {"Sxx", "=", N[Sxx]}}]](../HTMLFiles/index_685.gif)



![]()



![]()



![]()
Out[242]//TableForm=
| n | = | 2 |
| Sxy | = | {2.}-0.5 ({1.}+{{6654.,5712.},{1.,6.6},{3.385,44.5},{0.92,5.7},{2547.,4603.},{10.55,179.5},{0.023,0.3},{160.,169.},{3.3,25.6},{52.16,440.},{0.425,6.4},{465.,423.},{0.55,2.4},{187.1,419.},{0.075,1.2},{3.,25.},{0.785,3.5},{0.2,5.},{1.41,17.5},{60.,81.},{529.,680.},{27.66,115.},{0.12,1.},{207.,406.},{85.,325.},{36.33,119.5},{0.101,4.},{1.04,5.5},{521.,655.},{100.,157.},{35.,56.},{0.005,0.14},{0.01,0.25},{62.,1320.},{0.122,3.},{1.35,8.1},{0.023,0.4},{0.048,0.33},{1.7,6.3},{3.5,10.8},{250.,490.},{0.48,15.5},{10.,115.},{1.62,11.4},{192.,180.},{2.5,12.1},{4.288,39.2},{0.28,1.9},{4.235,50.4},{6.8,179.},{0.75,12.3},{3.6,21.},{83.,98.2},{55.5,175.},{1.4,12.5},{0.06,1.},{0.9,2.6},{2.,12.3},{0.104,2.5},{4.19,58.},{3.5,3.9},{4.05,17.}}) ({2.}+{{6654.,5712.},{1.,6.6},{3.385,44.5},{0.92,5.7},{2547.,4603.},{10.55,179.5},{0.023,0.3},{160.,169.},{3.3,25.6},{52.16,440.},{0.425,6.4},{465.,423.},{0.55,2.4},{187.1,419.},{0.075,1.2},{3.,25.},{0.785,3.5},{0.2,5.},{1.41,17.5},{60.,81.},{529.,680.},{27.66,115.},{0.12,1.},{207.,406.},{85.,325.},{36.33,119.5},{0.101,4.},{1.04,5.5},{521.,655.},{100.,157.},{35.,56.},{0.005,0.14},{0.01,0.25},{62.,1320.},{0.122,3.},{1.35,8.1},{0.023,0.4},{0.048,0.33},{1.7,6.3},{3.5,10.8},{250.,490.},{0.48,15.5},{10.,115.},{1.62,11.4},{192.,180.},{2.5,12.1},{4.288,39.2},{0.28,1.9},{4.235,50.4},{6.8,179.},{0.75,12.3},{3.6,21.},{83.,98.2},{55.5,175.},{1.4,12.5},{0.06,1.},{0.9,2.6},{2.,12.3},{0.104,2.5},{4.19,58.},{3.5,3.9},{4.05,17.}})+{{4.42757*10^^7,3.26269*10^^7},{1.,43.56},{11.4582,1980.25},{0.8464,32.49},{6.48721*10^^6,2.11876*10^^7},{111.303,32220.3},{0.000529,0.09},{25600.,28561.},{10.89,655.36},{2720.67,193600.},{0.180625,40.96},{216225.,178929.},{0.3025,5.76},{35006.4,175561.},{0.005625,1.44},{9.,625.},{0.616225,12.25},{0.04,25.},{1.9881,306.25},{3600.,6561.},{279841.,462400.},{765.076,13225.},{0.0144,1.},{42849.,164836.},{7225.,105625.},{1319.87,14280.3},{0.010201,16.},{1.0816,30.25},{271441.,429025.},{10000.,24649.},{1225.,3136.},{0.000025,0.0196},{0.0001,0.0625},{3844.,1.7424*10^^6},{0.014884,9.},{1.8225,65.61},{0.000529,0.16},{0.002304,0.1089},{2.89,39.69},{12.25,116.64},{62500.,240100.},{0.2304,240.25},{100.,13225.},{2.6244,129.96},{36864.,32400.},{6.25,146.41},{18.3869,1536.64},{0.0784,3.61},{17.9352,2540.16},{46.24,32041.},{0.5625,151.29},{12.96,441.},{6889.,9643.24},{3080.25,30625.},{1.96,156.25},{0.0036,1.},{0.81,6.76},{4.,151.29},{0.010816,6.25},{17.5561,3364.},{12.25,15.21},{16.4025,289.}} |
| Sxx | = |  |
Note: Be very cautious in entering the formulas shown here. While using the "traditional" summation notation makes the analogy to Devore's statement of the equations more clear, it is easy to introduce subtle errors in Mathematica using this form. A less error-prone approach is to state the summations as, e.g., Sum[ x[[ i ]]*y[[ i ]], {i,1,n}], where the limits of each part of the expression are explicitly shown.
and finally the actual coefficients of the fitted model.
In[243]:=

![]()
![TableForm[{{Slope b :, N[b_1]}, {Intercept b :, N[b_0]}}] 1 0](../HTMLFiles/index_701.gif)



![]()
Out[245]//TableForm=
 |
|
 |
(The estimated value of the third parameter of the model, ![]() , will be computed later.)
, will be computed later.)
These are based on the computational forms given by Devore. While Mathematica can handle the original forms directly, the computational forms are more numerically stable, which seems desirable.
Immediately, we display the resulting model superimposed on a plot of the data to get a visual check that the model is actually appropriate for the data.
See the discussion of graphics in the appendix for more detail on how this display is created.
In[246]:=
![modelPlot = Plot[b_0 + b_1 * xx, {xx, Min[x], Max[x]}, DisplayFunction→Identity] ;](../HTMLFiles/index_711.gif)
![Show[{modelPlot, dataPlot}, Prolog→ {PointSize[0.02]}, AxesLabel→axesnames, DisplayFunction->$DisplayFunction] ;](../HTMLFiles/index_712.gif)
![Plot :: plln : Limiting value ColumnTake[{{6654, 5712}, {1, 6.6}, «8», «52»}, {1}] in {xx, Min[x], Max[x]} is not a machine-size real number. More…](../HTMLFiles/index_713.gif)

Computing Residuals
The residuals are defined to be the actual value of the data minus the predicted value. They are useful as a check on how good the model is, and their numerical values will be useful in later computations.
In[248]:=
![]()
![]()



![]()
Out[249]=

In[250]:=
![^ ListPlot[Table[{x[[i]], residuals[[i]]}, {i, 1, n}], AxesLabel→ {"x", y- y}] ;](../HTMLFiles/index_722.gif)



![]()


![[Graphics:../HTMLFiles/index_729.gif]](../HTMLFiles/index_729.gif)
Based on our model, the residuals are the observed values of ε . We assumed ε to be normally distributed with mean zero and a constant standard deviation. If the plot of the residuals does not support this assumption, caution is indicated.
Estimating ![]() and
and ![]()
From the definition on page 512 we can compute estimates of the standard deviation of ε (noting that the summand is simply the ith residual):
In[251]:=
![]()
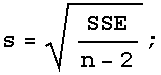
![]()
![]()
![]()



![]()
Out[254]//TableForm=
| SSE: |  |
| ComplexInfinity |
![]()
Coefficient of Determination
From the definitions on page 514, the total sum of squares and coefficient of determination, (![]() , but given the Mathematica name r2) are:
, but given the Mathematica name r2) are:
![]()
In[255]:=
![]()
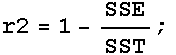
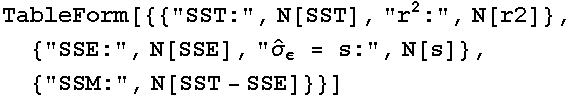




![]()
Out[257]//TableForm=
| SST: |  |
 |
|
| SSE: |  |
ComplexInfinity | |
| SSM: |  |
Values of ![]() near 1 indicate that the simple linear model explains most of the variability in the data. Be careful, though; departures from this can be caused by variability in the data (
near 1 indicate that the simple linear model explains most of the variability in the data. Be careful, though; departures from this can be caused by variability in the data (![]() is large) or by a mismatch between the model actually underlying the data and the assumed model of a line.
is large) or by a mismatch between the model actually underlying the data and the assumed model of a line.
Inferences on the Slope Parameter
The slope parameter ![]() is a measure of how much y changes for a unit change in x. If
is a measure of how much y changes for a unit change in x. If ![]() is actually zero, it means that changes in x do not really correspond to changes in y at all. So we compute a confidence interval on
is actually zero, it means that changes in x do not really correspond to changes in y at all. So we compute a confidence interval on ![]() to see if it's reasonable to say that
to see if it's reasonable to say that ![]() really is zero.
really is zero.
First we compute the critical value. This is the same problem as finding a confidence interval on the mean—except that in this case the number of degrees of freedom is different.
In[258]:=
![]()
![]()
![tstar = tstar/.FindRoot[∫_ (-∞)^tstarf[dummy, n - 2] dummy == 1 - α/2, {tstar, 2}] ;](../HTMLFiles/index_768.gif)
![]()
![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_774.gif)

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_817.gif)



![]()

![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_845.gif)

![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_847.gif)

![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_849.gif)
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_894.gif)



![]()

![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_922.gif)

![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_924.gif)

![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_926.gif)
![]()

![]()

![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_935.gif)

![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_937.gif)

![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_940.gif)
![]()
Out[261]//TableForm=
 |
The function f[x,ν] is the probability density function of a Student's T random variable with ν degrees of freedom (defined in an initialization cell in an appendix to this notebook). A graph of the relevant T distribution is shown below.
NOTE: The Mathematica commands to produce and label this graph are more complicated than the the plot itself is worth. Rather than try to teach this command, plot the distribution by itself, then draw in the relevant shading and labels.
In[262]:=

![Show :: gcomb : An error was encountered in combining the graphics objects in Show[{«1»}, DisplayFunction→ («1»&)] . More…](../HTMLFiles/index_946.gif)
A 100(1-α)% confidence interval for ![]() , the slope parameter of the regression model, is given by the formula on page 523 of Devore (noting that
, the slope parameter of the regression model, is given by the formula on page 523 of Devore (noting that ![]() is the value of
is the value of ![]() ):
):
In[263]:=
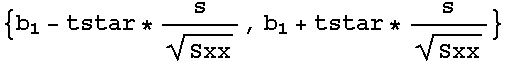
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_992.gif)



![]()

![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1020.gif)

![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1022.gif)

![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1024.gif)
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1065.gif)



![]()

![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1093.gif)

![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1095.gif)

![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1097.gif)
![]()

![]()
Out[263]=
![]()
If this confidence interval includes zero, the explanatory power of the model is suspect; the possibility that the supposedly dependent variable is in fact independent of the predictor variable is plausible based on the data.
Model Utility Test
The model utility test continues the same investigation as the confidence interval just computed. It is a hypothesis test comparing
![]() :
: ![]() = 0
= 0 ![]() :
: ![]() ≠0
≠0
The test statistic is
In[264]:=
![t_MUT = N[(b_1 - 0)/s/Sxx^(1/2)]](../HTMLFiles/index_1106.gif)
Out[264]=
![]()
With the corresponding P-value (recalling that since ![]() is
is ![]() ≠0, this is a two-sided test)
≠0, this is a two-sided test)
In[265]:=
![p_MUT = 2 * ∫_ (-∞)^(-Abs[t_MUT]) f[dummy, n - 2] dummy](../HTMLFiles/index_1110.gif)
Out[265]=
![2 ∫_ (-∞)^0.f[dummy, 0] dummy](../HTMLFiles/index_1111.gif)
which has the usual interpretation that smaller P-values provide stronger support for the alternate hypothesis that ![]() is not zero. In general, rejecting the null hypothesis provides support that the predictor variable is useful in explaining the changes in the response variable.
is not zero. In general, rejecting the null hypothesis provides support that the predictor variable is useful in explaining the changes in the response variable.
Prediction of Y
Specific Values of Y Given Specific Values of X
Predicting a specific value of Y given a specific value x is exactly what our model is about. So making this computation is as simple as substituting into the basic model (setting ε to 0).
In[266]:=
![]()

Out[266]=
![]()
In[267]:=
![]()
Out[267]=

Extrapolation—predicting a y value based on an x value that is beyond the observed data in either direction—is mechanically easy, but dangerous. Since the pair of interest is outside our experience, we have no way to judge whether extending the linear model out to this point is reasonable or not. Don't extrapolate!
In[268]:=
![TableForm[{{"Data range:", Min[x], "≤ x ≤", Max[x]}}]](../HTMLFiles/index_1118.gif)
Out[268]//TableForm=
| Data range: | ColumnTake[{{6654,5712},{1,6.6},{3.385,44.5},{0.92,5.7},{2547,4603},{10.55,179.5},{0.023,0.3},{160,169},{3.3,25.6},{52.16,440},{0.425,6.4},{465,423},{0.55,2.4},{187.1,419},{0.075,1.2},{3,25},{0.785,3.5},{0.2,5},{1.41,17.5},{60,81},{529,680},{27.66,115},{0.12,1},{207,406},{85,325},{36.33,119.5},{0.101,4},{1.04,5.5},{521,655},{100,157},{35,56},{0.005,0.14},{0.01,0.25},{62,1320},{0.122,3},{1.35,8.1},{0.023,0.4},{0.048,0.33},{1.7,6.3},{3.5,10.8},{250,490},{0.48,15.5},{10,115},{1.62,11.4},{192,180},{2.5,12.1},{4.288,39.2},{0.28,1.9},{4.235,50.4},{6.8,179},{0.75,12.3},{3.6,21},{83,98.2},{55.5,175},{1.4,12.5},{0.06,1},{0.9,2.6},{2,12.3},{0.104,2.5},{4.19,58},{3.5,3.9},{4.05,17}},{1}] | ≤ x ≤ | ColumnTake[{{6654,5712},{1,6.6},{3.385,44.5},{0.92,5.7},{2547,4603},{10.55,179.5},{0.023,0.3},{160,169},{3.3,25.6},{52.16,440},{0.425,6.4},{465,423},{0.55,2.4},{187.1,419},{0.075,1.2},{3,25},{0.785,3.5},{0.2,5},{1.41,17.5},{60,81},{529,680},{27.66,115},{0.12,1},{207,406},{85,325},{36.33,119.5},{0.101,4},{1.04,5.5},{521,655},{100,157},{35,56},{0.005,0.14},{0.01,0.25},{62,1320},{0.122,3},{1.35,8.1},{0.023,0.4},{0.048,0.33},{1.7,6.3},{3.5,10.8},{250,490},{0.48,15.5},{10,115},{1.62,11.4},{192,180},{2.5,12.1},{4.288,39.2},{0.28,1.9},{4.235,50.4},{6.8,179},{0.75,12.3},{3.6,21},{83,98.2},{55.5,175},{1.4,12.5},{0.06,1},{0.9,2.6},{2,12.3},{0.104,2.5},{4.19,58},{3.5,3.9},{4.05,17}},{1}] |
Prediction Interval on a Future Value
As shown above, a predicted value for Y at a specific value ![]() is found by substituting into the model. Devore shows that (assuming
is found by substituting into the model. Devore shows that (assuming ![]() and
and ![]() are themselves unbiased, which is true given our computational forumulæ and the assumed distribution of ε ) the expected value of this predicted value is indeed
are themselves unbiased, which is true given our computational forumulæ and the assumed distribution of ε ) the expected value of this predicted value is indeed ![]() +
+![]()
![]() as desired. Given this and the distribution of an appropriate standardized statistic, we can compute a 100(1-α)% confidence interval for Y(
as desired. Given this and the distribution of an appropriate standardized statistic, we can compute a 100(1-α)% confidence interval for Y(![]() )
)
![T = (Overscript[Y,^] - (β_0 + β_1x^*))/S_Overscript[Y,^] ~ T_ (n - 2)](../HTMLFiles/index_1126.gif)
First, we compute the standard error of the predicted Y value:
In[269]:=
![Overscript[σ,^] _ (Overscript[Y,^] | x^*) = s_Overscript[Y,^] = s (1/n + (xstar - Mean[x])^2/Sxx)^(1/2)](../HTMLFiles/index_1127.gif)
Out[269]=
![]()
At this point we could compute a confidence interval on E(![]() ) following Equation 12.6 on page 532. However, that's not what we're after; we want a prediction interval on a future y value.
) following Equation 12.6 on page 532. However, that's not what we're after; we want a prediction interval on a future y value.
Once again, we need to find the T critical value, labeled "tstarpredict" (to allow it to be different than the critical value we computed above)
In[270]:=
![]()
![tstarpredict = tstar/.FindRoot[∫_tstar^∞f_T[dummy, n - 2] dummy == (1 - confidencepredict)/2, {tstar, 2}]](../HTMLFiles/index_1131.gif)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1173.gif)



![]()

![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1201.gif)

![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1203.gif)

![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1205.gif)
![]()

![]()
Out[271]=

The prediction interval is (Equation 12.7 on page 535)
In[272]:=
![{b_0 + b_1 * xstar - tstarpredict * ((s)^2 + (s_Overscript[Y,^])^2)^(1/2), b_0 + b_1 * xstar + tstarpredict * ((s)^2 + (s_Overscript[Y,^])^2)^(1/2)}](../HTMLFiles/index_1210.gif)

![]()
![]()
![]()
![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1216.gif)

![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1218.gif)

![]()
![FindRoot :: nlnum : The function value {-0.975 + NIntegrate[f[dummy, 0], {dummy, «1», 2.}]} is not a list of numbers with dimensions {1} at {tstar} = {2.} . More…](../HTMLFiles/index_1221.gif)
![]()
![]()
![]()
Out[272]=
![]()
and as expected, the predicted value is in the center of the interval.
In[273]:=
![]()
Out[273]=

Results
To summarize our results:
We are fitting the model Y = ![]() +
+ ![]() x + ε to the observed data. Our estimates for
x + ε to the observed data. Our estimates for ![]() ,
, ![]() , and
, and ![]() , together with other relevant measures, are:
, together with other relevant measures, are:
In[274]:=
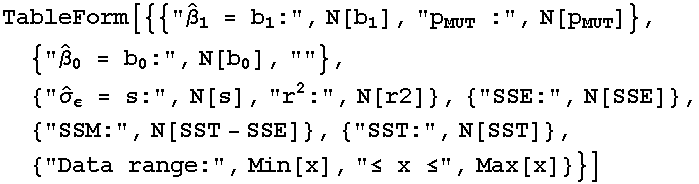



![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Out[274]//TableForm=
 |
2. NIntegrate[f[dummy,0],{dummy,-∞,0.}] | ||
 |
|||
| ComplexInfinity |  |
||
| SSE: |  |
||
| SSM: |  |
||
| SST: |  |
||
| Data range: | ColumnTake[{{6654,5712},{1,6.6},{3.385,44.5},{0.92,5.7},{2547,4603},{10.55,179.5},{0.023,0.3},{160,169},{3.3,25.6},{52.16,440},{0.425,6.4},{465,423},{0.55,2.4},{187.1,419},{0.075,1.2},{3,25},{0.785,3.5},{0.2,5},{1.41,17.5},{60,81},{529,680},{27.66,115},{0.12,1},{207,406},{85,325},{36.33,119.5},{0.101,4},{1.04,5.5},{521,655},{100,157},{35,56},{0.005,0.14},{0.01,0.25},{62,1320},{0.122,3},{1.35,8.1},{0.023,0.4},{0.048,0.33},{1.7,6.3},{3.5,10.8},{250,490},{0.48,15.5},{10,115},{1.62,11.4},{192,180},{2.5,12.1},{4.288,39.2},{0.28,1.9},{4.235,50.4},{6.8,179},{0.75,12.3},{3.6,21},{83,98.2},{55.5,175},{1.4,12.5},{0.06,1},{0.9,2.6},{2,12.3},{0.104,2.5},{4.19,58},{3.5,3.9},{4.05,17}},{1}] | ≤ x ≤ | ColumnTake[{{6654,5712},{1,6.6},{3.385,44.5},{0.92,5.7},{2547,4603},{10.55,179.5},{0.023,0.3},{160,169},{3.3,25.6},{52.16,440},{0.425,6.4},{465,423},{0.55,2.4},{187.1,419},{0.075,1.2},{3,25},{0.785,3.5},{0.2,5},{1.41,17.5},{60,81},{529,680},{27.66,115},{0.12,1},{207,406},{85,325},{36.33,119.5},{0.101,4},{1.04,5.5},{521,655},{100,157},{35,56},{0.005,0.14},{0.01,0.25},{62,1320},{0.122,3},{1.35,8.1},{0.023,0.4},{0.048,0.33},{1.7,6.3},{3.5,10.8},{250,490},{0.48,15.5},{10,115},{1.62,11.4},{192,180},{2.5,12.1},{4.288,39.2},{0.28,1.9},{4.235,50.4},{6.8,179},{0.75,12.3},{3.6,21},{83,98.2},{55.5,175},{1.4,12.5},{0.06,1},{0.9,2.6},{2,12.3},{0.104,2.5},{4.19,58},{3.5,3.9},{4.05,17}},{1}] |
The model and data together are shown below:
In[275]:=
![Show[{modelPlot, dataPlot}, {Prolog→ {PointSize[0.02]}, AxesLabel→axesnames, DisplayFunction->$DisplayFunction}] ;](../HTMLFiles/index_1257.gif)
![Plot :: plln : Limiting value ColumnTake[{{6654, 5712}, {1, 6.6}, «8», «52»}, {1}] in {xx, Min[x], Max[x]} is not a machine-size real number. More…](../HTMLFiles/index_1258.gif)

In[276]:=
![]()
Out[276]=
![]()
Appendix: Mathematica Definitions for Regression
This appendix is for other definitions that are needed in computations, Computation cells in this appendix are initialization cells, to be evaluated when the notebook is opened.
In[2]:=
![]()
![]()
Student's T distribution
In[4]:=
![f[x_, df_] := Gamma[(df + 1)/2]/Gamma[df/2] * 1/(df * π)^(1/2) * (1 + x^2/df)^(-(df + 1)/2)](../HTMLFiles/index_1264.gif)
In[280]:=
![]()
![]()
![]()
![]()
![]()
![[Graphics:../HTMLFiles/index_1270.gif]](../HTMLFiles/index_1270.gif)
Excel Solution
| Created by Mathematica (July 20, 2006) |